
过去六个月内,我的团队添加到日常工具栈中最有用的两款AI工具都来自中国:Moonshot AI的Kimi和Minimax。两者都真正令人惊艳,在各自擅长的领域都远超多款美国工具,现在都是Seahawk Media在2026年交付客户工作的关键组成部分。如果你还没试过其中任何一个,你就错过了真正的生产级能力。Moonshot AI and Minimax. Both are genuinely incredible, both run circles around several US tools at the specific things they do well, and both are now load-bearing parts of how Seahawk Media ships client work in 2026. If you have not tried either, you are missing real production-grade capability.
关键要点:用 Claude 或 GPT 提示,然后用 Kimi 进行深度研究,用 Minimax 制作完整应用原型,将数天的代理工作压缩到几分钟内。Prompt with Claude or GPT, then execute with Kimi for deep research and Minimax for full-app mockups, collapsing days of agency work into minutes.
我是从实操者的角度来写这篇文章的,而不是从模型基准测试的角度。我们每天也在使用Claude和GPT,我们并没有放弃它们。这里的观点更简单:在2026年正确使用Kimi和Minimax的方式是与Claude或GPT配合使用,而不是替代它们。一旦你调优了工作流程,两者在深度研究和设计原型方面的输出质量就能达到美国工具在同样单轮提示体验上还未能企及的水平。Claude and GPT every day too, and we are not switching off them. The argument here is simpler: the right way to use Kimi and Minimax in 2026 is alongside Claude or GPT, not in place of them, and once you have the workflow tuned the output quality on both deep research and design mockups is at a level US tools have not reached yet on the same single-prompt experience.
Kimi和Minimax是什么?
Kimi是Moonshot AI的消费者聊天产品。Moonshot AI是一家北京的AI实验室,因在2024年推出首个广泛应用的200万token上下文窗口模型而名声大噪。2025年末发布的Kimi K2版本增加了强大的代理和代码能力,Kimi Researcher产品是我的团队使用最频繁的深度研究代理。Kimi可免费用于一般用途,国际网页版无需中国手机号即可使用,这解决了2024年困扰大多数非中国团队的痛点。
Minimax是上海的AI实验室,开发了Hailuo(在Twitter上广为流传的视频生成产品)、MiniMax M1推理模型,以及MiniMax Agent产品——该产品能从单个提示词生成完整可用的网页应用演示和高保真UI原型。与Kimi一样,Minimax在消费者级别免费提供,并为集成工作提供付费API接入。
两家公司都开源了其技术栈中的重要部分。Kimi K2的权重在Hugging Face上公开。MiniMax-Text-01和MiniMax M1也是开放权重。在决定围绕哪些工具构建工作流时,这不是小细节:这意味着底层能力是可审计的,可以在必要时在你自己的基础设施上运行,而且不太可能一夜之间被公司付费墙的变更挡在身后。
我的团队如何使用Kimi进行深度研究
Kimi Researcher是我的团队在需要结构化研究输出而不是聊天回答时首先使用的深度研究模式。流程是:你描述问题,Kimi规划多步骤研究路径,执行网络搜索,逐字阅读源文档(长上下文确实是差异化因素),然后返回带引用的结构化报告。一项需要人类分析师花费三到四小时的研究工作在大约十二到十五分钟内就能产生可比的输出。
我们每周运行的具体使用场景:客户提案的竞争分析简报、早期初创公司工作的市场规模备忘录、我们即将发布页面的新领域技术景观审查,以及我们在HostList.io上发布的长篇内容的编辑简报。输出质量足够高,以至于曾经从事这项工作的分析师现在将时间花在验证和重新框架化而不是信息收集上。这是真正的生产力提升。
Kimi的不足之处:语调校准。Kimi输出的默认语音读起来略显翻译感、略显正式、略显委员会风格。我们总是在输出进入任何客户交付物之前通过Claude进行语调和结构重写。Kimi负责收集和综合;Claude负责打磨和人性化。这个两步骤过程就是我们的工作流。
我的团队如何使用Minimax进行设计模型
Minimax Agent是过去六个月里让我最惊讶的工具。你用纯英文描述一个界面,如果有的话给它一个品牌参考,大约三十到九十秒后,你就能得到一个完全可工作的HTML和Tailwind原型,你可以点击浏览。不是截图。不是线框图。一个真正运行的应用,具有状态、导航和合理的组件设计。质量达到我可以将Minimax生成的模型直接发送到客户pitch演讲稿而无需进一步设计工作的程度。Tailwind prototype that you can click through. Not a screenshot. Not a wireframe. A real running app with state, navigation, and reasonable component design. The quality is at the level that I have shipped Minimax-generated mockups directly into client pitch decks without further design work.
下面是Minimax今天可以从单个提示中生成的UI密度和精度。这花了大约四十秒,没有手动样式编写,没有Figma,没有设计系统交接:
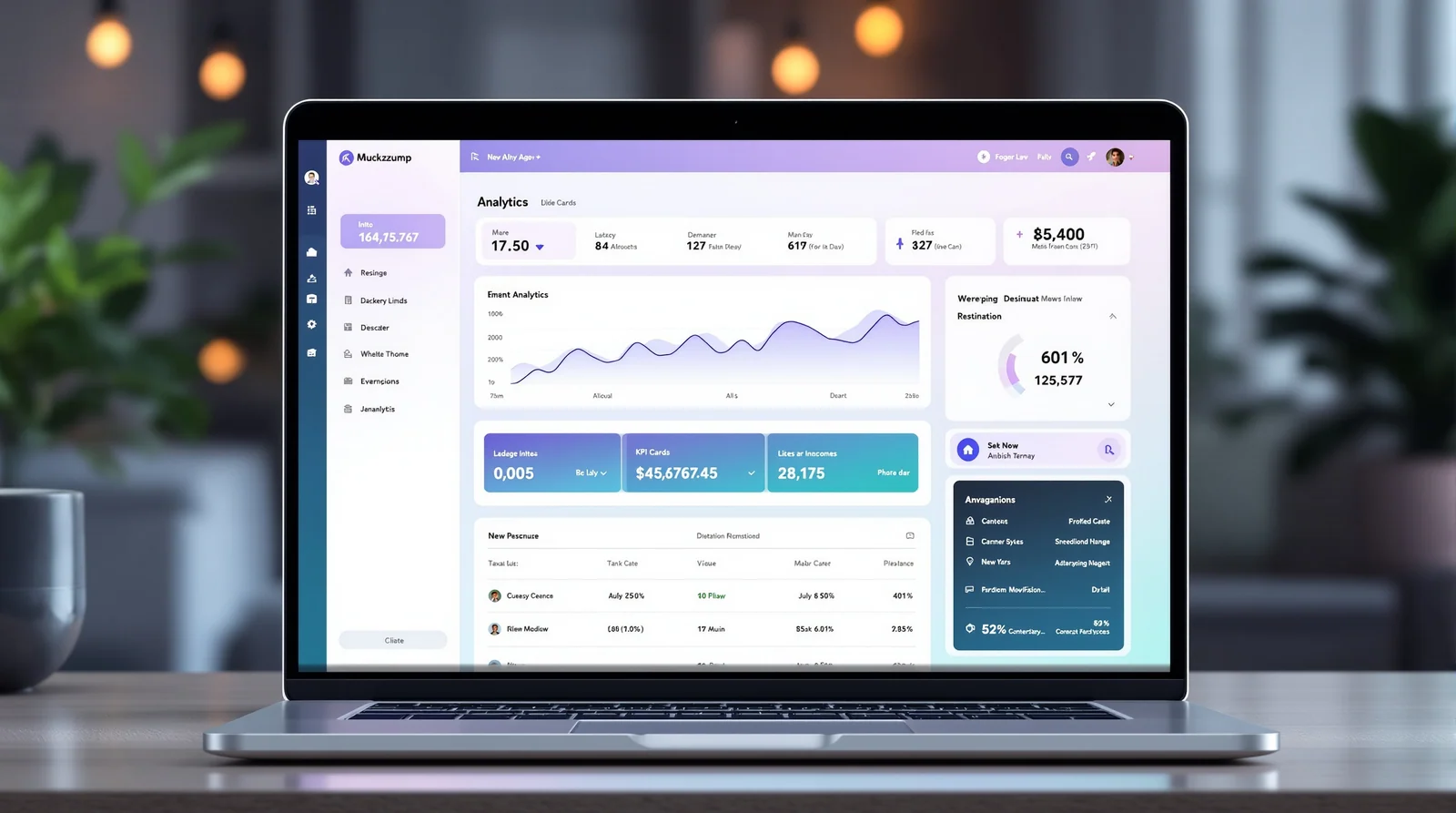
与十八个月前相当的工作流程相比:设计师在Figma中花费两天时间制作静态模型,开发者在代码中重建,原型在第五天才可点击。今天,赢的机构是那个可以在发现电话结束时在客户面前放置可工作原型的机构。
Minimax的不足之处:品牌精确度。开箱即用,设计语言是通用现代风格。如果你的客户有强大的现有视觉识别,你必须花时间在提示中描述排版、色彩、间距和组件约定,即使这样输出读起来也是模型的解释而不是品牌本身。对于还没有强大识别的早期客户,这是一个功能而不是缺陷。对于成熟品牌,你使用Minimax作为起点并在Figma中完成。
工作流:用 Claude 或 GPT 提示,用 Kimi 或 Minimax 构建
这些工具给我带来的最大突破来自于一个认识:给 Kimi 和 Minimax 写的最好提示词不是手工写的。它们是由 Claude 或 GPT 写的。事后看来这很明显;但实际付诸行动花了我一个月的时间。
流程是这样的。我用三四句话向 Claude 描述目标。我让 Claude 为给定目标写一个针对 Kimi Researcher(或 Minimax Agent)的最优提示词,包括我想要的输出结构、约束条件、语气,以及任何要锚定的具体来源或组件模式。Claude 写出一份四百字的提示词,比我自己花五分钟写的任何东西都更精确。我把它粘贴到 Kimi 或 Minimax 里,输出质量明显好于我直接提示的情况。
这个模式——用一个模型进行提示工程,用另一个模型执行——是我的团队在过去十二个月里采用的最高杠杆工作流。它有效是因为 Claude 和 GPT 非常擅长元任务(规划、结构化、为其他系统编写指令),而 Kimi 和 Minimax 非常擅长执行型任务(运行研究路径、生成可用界面)。让每个工具做它最擅长的事。
我们每周运行的具体用例
Seahawk Media 最近两周的五个具体例子:
为 B2B SaaS 投融资准备的竞争格局简报,Claude 提示、Kimi 执行、Claude 改写。总共两小时,而同样的简报以前需要两天。客户说这是他们从任何代理机构收到的最好的竞争备忘录。
为目录网站提案构建的可点击演示,从六行描述出发用 Minimax Agent 构建。四十秒出现第一个原型,二十分钟迭代,一个包含三个屏幕的可用演示交付给客户。客户在日历周结束前签署了合同。
编辑日历的内部管理仪表板,从数据模型的描述用 Minimax Agent 构建。经过大约一小时的打磨后,输出质量已经足以交付给团队。从想法到可用内部工具的总耗时:不足九十分钟。
程序化 SEO 项目的翻译质量审查,Kimi 跨数千条翻译字符串处理长上下文交叉检查。捕获细微错误翻译的成本降至大约一次 Kimi 运行的成本。
无头CMS定价模型的技术景观审查。用Kimi研究员花十二分钟,Claude重写了输出,简报第二天就成了公开文章的基础。
为什么这些中国AI工具在完整应用生成上领先
我对模型架构没有特殊洞察,但产品间的模式是一致的。中国消费级AI产品在单次提示完成复杂多模态任务上的优化力度,比美国同行产品更大。Claude Artifacts在聊天内的迭代编码上表现出色。ChatGPT canvas在协作文档工作上表现出色。两者都不是为单个提示生成可点击运行的完整原型这个理念设计的。Claude Artifacts is excellent for iterative coding inside a chat. ChatGPT canvas is excellent for collaborative document work. Neither is designed around the idea that a single prompt should produce a fully running prototype that you click through.
Minimax就是。产品界面、模型行为、输出格式,一切都是为完整应用生成这一主要工作流设计的,而不是众多功能之一。Kimi研究员也是如此:它是为端到端研究运行专门设计的,而不是碰巧能做研究的聊天轮次。当一个工具围绕特定能力而设计,而不是把它作为可选项提供时,该特定能力上的质量往往会领先。
地缘政治是真实的,值得坦诚说出来。关于数据驻留、美国出口管制、通过中国基础设施运行客户工作意味着什么,有合理的讨论要进行。我们不会通过任何一个工具传输机密客户数据。公开市场研究、品牌无关的设计简报、内部工具都可以用。这种心态没有显著拖累我们。
这对2026年的代理机构工作意味着什么
两天的模型消失了。四小时的竞争备忘录消失了。一周的技术景观审查消失了。任何仍然以旧速率和时间表对这些工作流进行计费的代理机构,都在与已经将成本结构折叠了一个数量级的代理机构竞争。工作没有消失;杠杆转移到了知道用哪个工具解决哪个问题的运营者手中。
我对接下来十二个月的看法:赢的代理机构将是那些在团队中有明确的AI工作流文档和排练的,而不是那些有最好个人操作者临时使用AI的。工作流杠杆会复合增长。个人生产力提升不会。
底线
Kimi和Minimax是真实的生产级工具,都可以免费开始,都值得本周加入你的技术栈。用Claude或GPT来提示词工程它们。用Kimi做深度研究。用Minimax做设计模型和完整应用生成。这个组合是我自从Claude推出Sonnet 3.5以来加入的最有用的AI工作流。
再说两点公道话。第一,这些产品迭代很快,我这里描述的具体功能界面三个月后会不一样。但工作流的形状不会变。第二,我和这两家公司都没有商业关系;这是一个伦敦创意机构主理人的日常技术栈——我什么都试试,只留下能经得起推敲的东西。
两个都试试。在你自己的任务上老老实实地和Claude、GPT做对比。留下赢家。这是唯一靠得住的框架,用来在这个六周一次排名大洗牌的年代选择AI工具。
相关阅读
2026年的提示词工程:是什么、能挣多少、往哪儿去
用Claude设计软件:从头脑风暴到规格说明的工作流
2026年的AEO和GEO:实用手册
常见问题
Kimi和Minimax是什么?
Kimi(由Moonshot AI开发)和Minimax是两个中文AI工具。Kimi用于深度研究,Minimax用于全应用设计原型。这两个工具在各自的特定任务上表现出与美国工具相当,有时甚至超越美国工具在日常代理机构使用中的水平。
Kimi适合深度研究吗?
在这个工作流中,是的。Kimi在长文本、多源研究方面表现出色,在日常工作中专门用于这类任务。做法是先用Claude或GPT进行提示和规划,然后用Kimi进行繁重的研究工作,这样是结合各工具的优势,而不是依赖单一工具。
Minimax用于什么?
Minimax用于设计原型,特别是全应用生成,在这方面领先于多个美国工具。模式是用Claude或GPT完善简报,然后在Minimax中构建视觉原型,比通用工具在全应用设计上的速度更快。
代理机构应该使用Kimi和Minimax这样的中文AI工具吗?
对于特定任务,值得进行测试,因为它们分别在深度研究和全应用原型方面处于领先地位。在使用客户工作时,像评估任何第三方工具一样,权衡数据和隐私考虑,选择在性能上确实超群的工具使用,而不是默认使用。